Scaling dexterous manipulation requires generalization across objects, scenes, and tasks,
yet existing data sources face a trade-off between scale and scene/embodiment alignment:
teleoperation data is well aligned with robot deployment but expensive to collect;
simulation is scalable but limited by the sim-to-real gap; and real egocentric videos
scale effectively but remain misaligned with robot deployment.
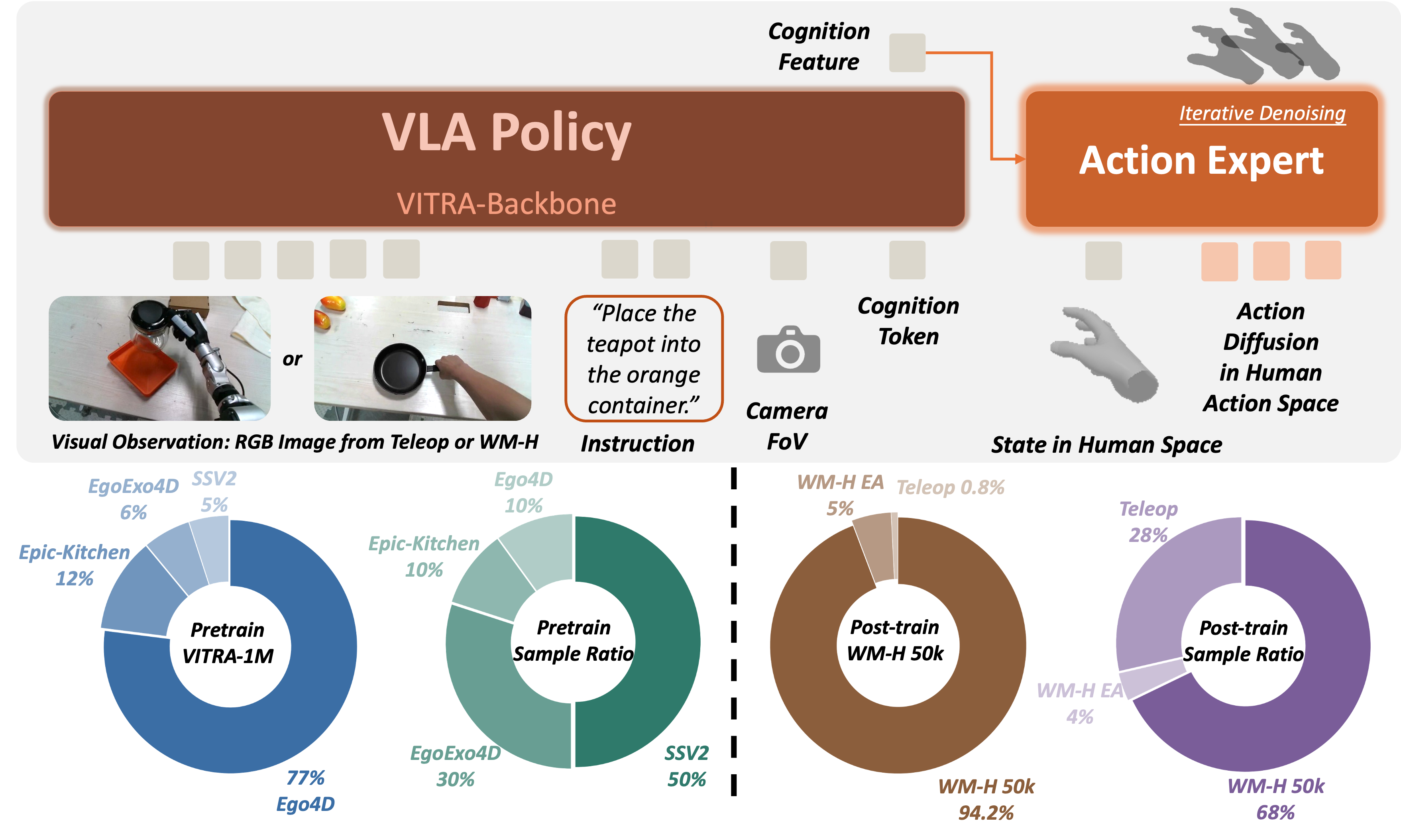
We propose Wh0, a framework that uses generative video world models as
scalable and controllable sources of egocentric human-hand manipulation data to unlock
the manipulation capabilities of pretrained dexterous VLA models. Conditioned on language,
objects, and scenes, Wh0 uses a generative world model to produce WM-H,
a 50k-episode dataset of egocentric human-object interaction videos. Wh0 then converts
the generated videos into robot-trainable supervision through hand motion reconstruction
and visual editing. Co-trained with a limited amount of real robot data, WM-H adapts
pretrained VLA models to dexterous manipulation deployment. Across 18 real-world dexterous
manipulation tasks, compared with a model post-trained only on robot data, Wh0 improves
zero-shot success on unseen tasks from 8.3% to 38.9%. Ablation studies further show that
scalable generation and scene/embodiment alignment are key drivers of performance gains.